-
[Python] Higher-Order Functions와 Generator로 Django FCM 코드 중복 제거IT 2026. 1. 21. 10:33
문제 인식
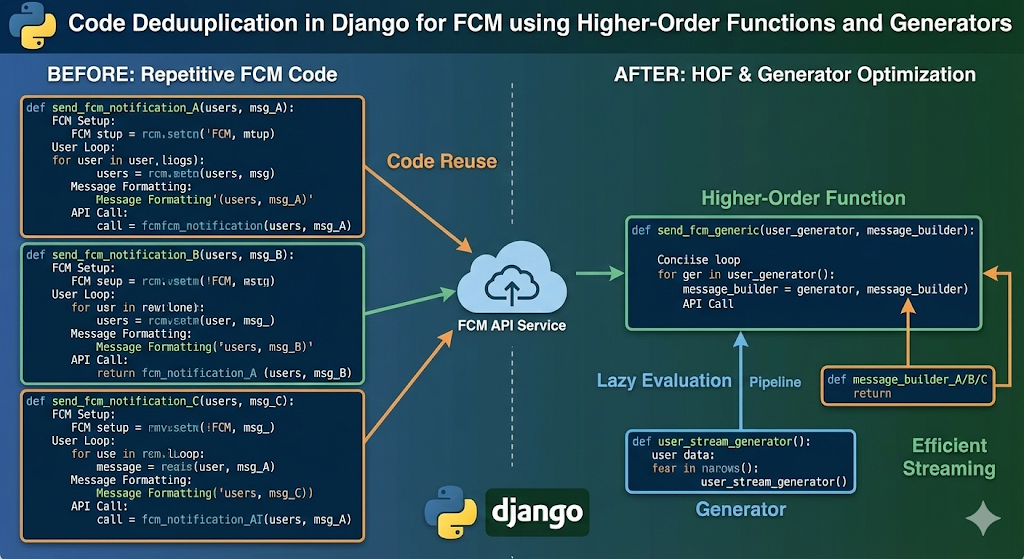
Django 프로젝트의 FCM(Firebase Cloud Messaging) 발송 로직을 분석한 결과, 몇몇 함수에서 동일한 패턴이 반복되고 있었습니다.
모든 함수가 동일 구조를 따르고 있었으며, 차이점은 메세지 내용 뿐이었습니다. 이는 전형적인 DRY(Don't Repeat Yourself) 원칙 위반 사례입니다.
반복 패턴 분석
중복 함수는 다음과 같은 공통 로직을 포함하고 있었습니다.
DB 조회 -> 사용자 검증 -> 알림 설정 확인 -> 알림 레코드 생성 -> FCM 발송 -> 발송 상태 업데이트
Solution 1: Decorator Pattern with Higher-Order Functions
구현
Python의 데코레이터를 활용하여 공통 로직을 추상화했습니다. 데코레이터는 함수를 인자로 받아 새로운 함수를 반환하는 고차함수입니다.
**리팩토링 전 (85줄)** ```python def send_order_complete_notification(order_id): try: order = Order.objects.select_related('user').get(id=order_id) except Order.DoesNotExist: logger.error("주문을 찾을 수 없음") return {'success': False} if not order.user: return {'success': False} if not order.user.is_notification_enabled: return {'success': False} notification = Notification.objects.create( user=order.user, title="주문이 완료되었습니다", message="상품이 배송 준비 중입니다", notification_type='ORDER_COMPLETE', reference_id=order.id # ... 10줄 더 ) success = send_fcm_message( token=order.user.fcm_token, title="주문이 완료되었습니다", message="상품이 배송 준비 중입니다", data={'order_id': order.id} # ... 10줄 더 ) if success: notification.is_sent = True notification.save() return {'success': success} ``` **리팩토링 후 (15줄)** ```python @notification_sender(model=Order, select_related=['user']) def send_order_complete_notification(order, user): return { 'title': "주문이 완료되었습니다", 'message': "상품이 배송 준비 중입니다", 'data': {'order_id': order.id} } ``` ### 데코레이터 구현 ```python def notification_sender(model, select_related=None, user_field='user'): """ FCM 발송을 위한 데코레이터 Args: model: Django 모델 클래스 select_related: 쿼리 최적화를 위한 관계 필드 user_field: 사용자 참조 필드명 """ def decorator(message_func): def wrapper(object_id, **kwargs): # 1. 쿼리 최적화 queryset = model.objects if select_related: queryset = queryset.select_related(*select_related) obj = queryset.get(id=object_id) # 2. 사용자 검증 user = getattr(obj, user_field) if not user or not user.is_notification_enabled: return {'success': False} # 3. 메시지 설정 획득 config = message_func(obj, user, **kwargs) # 4. 알림 레코드 생성 notification = Notification.objects.create( user=user, title=config['title'], message=config['message'], data=config.get('data', {}) ) # 5. FCM 발송 success = send_fcm_message( token=user.fcm_token, title=config['title'], message=config['message'], data=config.get('data', {}) ) # 6. 상태 업데이트 if success: notification.is_sent = True notification.save() return {'success': success} return wrapper return decorator ```이렇게 함으로써 아래와 같은 효과를 얻었습니다.
- 관심사 분리: 인프라 로직과 비즈니스 로직을 분리할 수 있게 되었습니다.
- 쿼리 최적화 강제: 데코레이터에서 select_related 자동 적용으로 N+1 쿼리를 방지했습니다.
- 코드 감소: 함수 리팩토링으로 중복 코드가 감소되었습니다.
Solution 2: Context Manager for Resource Management
구현
Context Manager의 '__enter__'와 '__exit__' 프로토콜을 활용하여 리소스 정리를 자동화했습니다.
**리팩토링 전 (45줄)** ```python def process_payment(payment_id): try: payment = Payment.objects.get(id=payment_id) result = gateway.charge(payment) except Exception as e: payment.status = 'FAILED' payment.save() refund_points(payment.user, payment.amount) delete_temp_order(payment.order_id) send_failure_notification(payment.user) raise ``` **리팩토링 후 (9줄)** ```python def process_payment(payment_id): with PaymentFailureHandler(payment_id): payment = Payment.objects.get(id=payment_id) result = gateway.charge(payment) ``` ### Context Manager 구현 ```python class PaymentFailureHandler: def __init__(self, payment_id): self.payment_id = payment_id def __enter__(self): return self def __exit__(self, exc_type, exc_val, exc_tb): """ exc_type: 예외 타입 (None이면 정상 종료) exc_val: 예외 객체 exc_tb: 예외 traceback """ if exc_type is None: return False # 실패 시 자동 정리 try: payment = Payment.objects.get(id=self.payment_id) payment.status = 'FAILED' payment.save() refund_points(payment.user, payment.amount) delete_temp_order(payment.order_id) send_failure_notification(payment.user) except Exception as cleanup_error: logger.error(f"정리 작업 실패: {cleanup_error}") return False # 예외 재발생으로 Celery retry 활성화 ```이렇게 함으로써 아래와 같은 효과를 얻었습니다.
- 원자성 보장: 정리 작업 누락이 불가능 합니다.
- 일관성 확보: 모든 실패 케이스에 동일한 처리를 적용합니다.
Solution 3: Generator로 메모리 효율 개선
공지사항을 전체 사용자에게 보낼 때 가장 큰 문제는 "메모리" 입니다.
기존 방식의 문제점
```python # 10만 명 사용자를 한 번에 메모리에 로드 users = User.objects.all() user_list = list(users) # ← 이 순간 메모리 500MB 사용 for i in range(0, len(user_list), 500): batch = user_list[i:i+500] send_batch_notification(batch) ```"list()" 호출 순간, Django ORM이 모든 데이터를 메모리에 로드 합니다.
예를 들어 10만 명이면 500MB, 100만 명이면 5GB를 잡아먹습니다.
Generator의 Lazy Evaluation
Generator는 필요한 순간에만 데이터를 생성하는 Python의 핵심 기능입니다.
**Before: Eager Loading (한 번에 다 로드)** ```python users = User.objects.all() user_list = list(users) # 10만 명 전부 메모리에 (500MB) for i in range(0, len(user_list), 500): batch = user_list[i:i+500] send_batch_notification(batch) ```**After: Lazy Evaluation (필요한 만큼만)** ```python users = User.objects.all() for batch in batch_queryset(users, batch_size=500): # 500명씩만 (5MB) send_batch_notification(batch) ```Generator 구현의 핵심
```python def batch_queryset(queryset, batch_size=500): """ Generator를 사용한 메모리 효율적인 배치 처리 yield 키워드가 핵심: - 함수 실행을 중단하고 값을 반환 - 다음 iteration에서 중단된 지점부터 재개 - 전체 데이터를 메모리에 올리지 않음 """ total = queryset.count() for offset in range(0, total, batch_size): # 이 순간에만 500개의 데이터를 DB에서 가져옴 batch = list(queryset[offset:offset + batch_size]) if not batch: break yield batch # 값을 반환하고 함수 실행 중단 # 다음 iteration 시 여기서부터 재개 ```Generator vs List: 메모리 사용량 비교
사용자 수 List (Eager) Generator (Lazy) 절감율 10만 명 500MB 5MB 90% 50만 명 2.5GB 5MB 99.8% 100만 명 5GB 5MB 99.9% 여기서 핵심은 Generator는 데이터 크기와 무관하게 일정한 메모리만을 사용한다는 것 입니다.
추가적인 이점은 다음과 같은데요
1. 메모리 효율 입니다. O(n) → O(batch_size)
2. 초기 지연이 감소되고, 즉 전체 로드를 기다릴 필요가 없습니다.
```python # Generator Chaining (파이프라인) active_users = User.objects.filter(is_active=True) for batch in batch_queryset(active_users, 500): for user in filter_by_region(batch): # 또 다른 Generator send_notification(user) # 메모리는 여전히 5MB만 사용 ```데코레이터 + Generator의 시너지
이 두 패턴을 함께 쓰면 더욱 좋습니다.
```python @batch_notification_sender(batch_size=500) def send_announcement_to_all(announcement): """ 데코레이터가: 1. Generator로 사용자를 500명씩 로드 2. Firebase Multicast API로 500명 동시 발송 3. 실패한 토큰 자동 처리 4. 발송 결과 로깅 """ return { 'title': announcement.title, 'message': announcement.content } ```개발자는 메세지 내용만 정의하면, 나머지는 초기 설정 이후 전부 자동입니다.
백엔드 개발자의 고민: 추상화의 적정선
모든 함수를 위에서 말한 형식으로 바꿀 수 있을까요? 아니요, 그러면 안됩니다.
저는 18개의 함수 중 9개만 리팩토링하고 나머지는 그대로 뒀습니다. 왜일까여?
억지로 끼워 맞추면 더 복잡해진다.
댓글 알림 함수를 예를 들어보겠습니다.
```python def send_comment_notification(comment_id): comment = Comment.objects.get(id=comment_id) # 댓글이 답글이냐에 따라 수신자가 다름 recipients = set() if comment.parent_id: # 답글인 경우 recipients.add(comment.parent.author) # 원 댓글 작성자 recipients.add(comment.post.author) # 게시글 작성자 # 같은 글에 댓글 단 다른 사람들 other_commenters = Comment.objects.filter( post=comment.post ).exclude(author=comment.author).values_list('author', flat=True) recipients.update(other_commenters) else: # 일반 댓글인 경우 recipients.add(comment.post.author) # 게시글 작성자만 # 동적으로 계산된 다수의 수신자 for recipient in recipients: send_fcm_notification(recipient, message) ```이거는 "누구에게 보낼 것 인가"를 동적으로 계산해야 합니다.
방금 설정한 데코레이터는 "한 명에게 보내기"를 전제로 설계 했기 때문에, 이걸 억지로 맞추면 오히려 더 복잡해집니다.
그래서 추상화의 수준의 선택 기준은
- 단일 수신자, 고정된 발송 흐름, 메세지 내용만 다른 것으로 했구요.
원래대로 둔 케이스는 다중 수신자 (동적 계산), 조건부 로직 (A면 B, C면 D), 특수한 전처리 필요 등에 해당됩니다.
좋은 추상화는 대다수의 케이스를 단순하게 만드는 것이고, 나머지를 억지로 끼워맞추려다 보면, 추상화 자체가 복잡해져서 오히려 역효과가 납니다.
실무에서의 Trade-off
Generator를 쓰면 메모리는 절약되지만, 총 실행 시간은 약간 증가 할 수 있습니다.
그러나 DB 왕복 횟수가 늘어나지만, 실제로는 시간의에 대한 처리가 거의 차이가 없습니다.
오히려 메모리 부족으로 인한 Swap이나 GC 오버헤드가 더 큰 문제였습니다.
타입 안정성
데코레이터를 쓰면서 TypeVar와 Generic을 활용해 타입 안정성도 확보했습니다.
```python from typing import TypeVar, Generic, Iterator, QuerySet T = TypeVar('T') def batch_queryset( queryset: QuerySet[T], batch_size: int = 500 ) -> Iterator[list[T]]: """ IDE가 자동완성을 제공: - QuerySet[User] → Iterator[list[User]] - QuerySet[Order] → Iterator[list[Order]] """ ... ```이제 IDE가 타입을 추론해서 자동완성을 정확하게 제공합니다.
그래서 이번 개선은 DRY 원칙을 실천했고, 관심사를 분리했습니다. 그리고 메모리를 줄인 개선을 했습니다아.
이번 리팩토링으로 모든 문제가 해결됐다고 생각하지는 않고, 새로운 엣지 케이스가 나타날 수 도 있다 생각합니다.
이번 블로그는 여기까지 입니다.
읽어주셔서 감사합니다.
적용된 패턴
- Higher-Order Functions (고차 함수 / 데코레이터)
- Context Manager (`with` 문 / `__enter__`/`__exit__` 프로토콜)
- Generator (lazy evaluation / `yield` 키워드)
- Type Hints (Generic / TypeVar)
'IT' 카테고리의 다른 글
[Python] 고차함수(Higher-Order Function) 란? (0) 2026.01.21 [Python] 파이썬 데코레이터(decorator)를 제대로 이해해보자 (0) 2026.01.21 블로그 7개월. 공백의 이유 (0) 2026.01.09 [Flutter] 크로스 플랫폼의 함정: Android 15 대응이 iOS UI를 망가뜨렸을 때 (1) 2025.06.23 [Flutter] Android 15의 Edge-to-Edge 완벽 정복기 (0) 2025.06.23